仕事
GoogleColaboratoryでPython② Webサイトからデータを取得してみよう!
ごじゃっぺ

前回、Google ColaboratoryでPythonを実行するための基本的な設定についてご説明しました。今回は、Webサイトからデータを取得するスクレイピングについて説明したいと思います。
必要なライブラリ
今回は、RequestsとBeautifulSoupというライブラリを使用します。GoogleColaboratoryには主要なライブラリがインストールされているので、事前にインストールをする必要はありません。
ライブラリの機能
それぞれのライブラリの機能について説明します。
- Requests・・・Webサイトのデータを取得することができます。
- BeautifulSoup・・・Requestsで取得したデータからBeautifulSoupオブジェクトを生成することで、HTMLデータの構文を解析することが可能。例えば、タグやクラス名を指定してデータを抽出することができます。
ライブラリのインポート
初めに使用するライブラリをインポートします。

Webサイトからデータを取得する
さっそく、実際のWebサイトからデータを取得してみましょう。今回はこの記事を掲載しているWaMのサイトから、コラム一覧ページ(https://wam-pjt.jp/colum/)のデータを取得してみましょう。
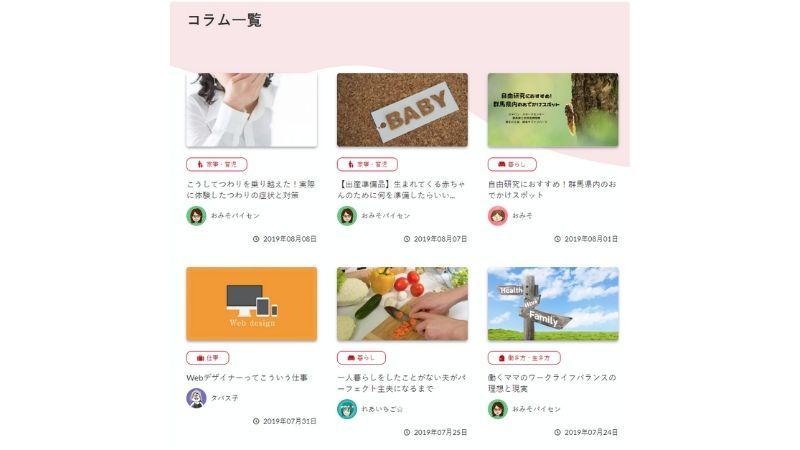
サイトからHTMLデータを取得する
まずは目的のサイトからデータを取得しましょう。

- 目的のサイトのURLを変数にセットする
- Requestsのgetメソッドで先ほどの変数を指定し、指定したサイトのデータを取得する
- textメソッドを実行して、取得したデータの内容をBeautifulSoupオブジェクトとして生成する
BeautifulSoupオブジェクトから必要なデータを取り出す
では、BeautifulSoupオブジェクトから必要なデータを取り出してみましょう。例えば、コラムのタイトルを取り出す場合には、タイトルのタグとクラス名を指定する必要があります。

クラス名は、ブラウザの「検証」モードで知ることができます。今回の場合、コラムタイトルのタグは「h2」、クラス名は「articleEntry__title」であることが分かります。ではタグとクラスを指定してタイトルを取得してみましょう。
そこでBeautifulSoupオブジェクトのfind_allメソッドを使用して、h2タグのarticleEntry__titleクラスを指定し、コラムのタイトルを取り出します。

- BeautifulSoupオブジェクトのfind_allメソッドで、タグ(h2)、クラス名(articleEntry__title)を指定し、ページ内の全てのコラムタイトルを取得する
- 取得した内容をprintで出力し、内容を確認
取得した内容をprintで出力した結果がこちらです。コラムのタイトルが取得できたことが分かります。

まとめ
いかがでしたか?今回は、Webサイトにアクセスし目的のデータをスクレイピングする方法について簡単に説明しました。BeautifulSoupを使えば、簡単にHTMLデータを取得できることがご理解頂けたと思います。次回は取得したデータをcsvファイルに保存する方法を説明したいと思います。


