仕事
Google ColaboratoryでPython③ Webサイトから取得したデータをCSVに保存
ごじゃっぺ

前回、Google ColaboratoryでPythonを実行してWebサイトからデータを取得するスクレイピングについてご説明しました。今回は、Webサイトから取得したデータをCSVファイルに保存する方法をご説明したいと思います。
必要なライブラリ
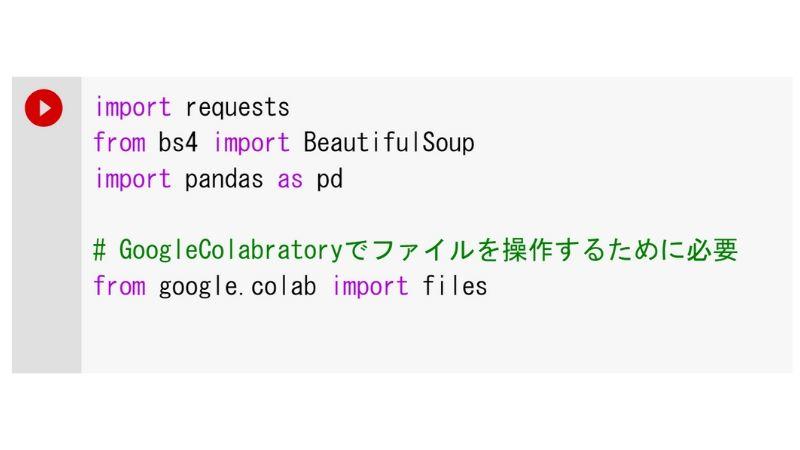
前回説明したrequestsとBeautifulSoupに加え、新たにpandasというライブラリとGoogle Colaboratoryのファイル操作のためのライブラリであるfilesを使用します。
ライブラリの機能
各ライブラリの機能について説明します。
- pandas・・・データ解析を支援する機能を持つライブラリです。今回はpandasのDataFrameオブジェクトに取得したデータをセットして使用します。DataFrameオブジェクトには表のようなイメージでデータを格納することができます。
- files・・・Google Colaboratoryでファイルへの読み書きなどファイル操作をするために必要なライブラリです。
ライブラリのインポート
初めに使用するライブラリをインポートします。
Webサイトから取得したデータをCSVファイルに保存する
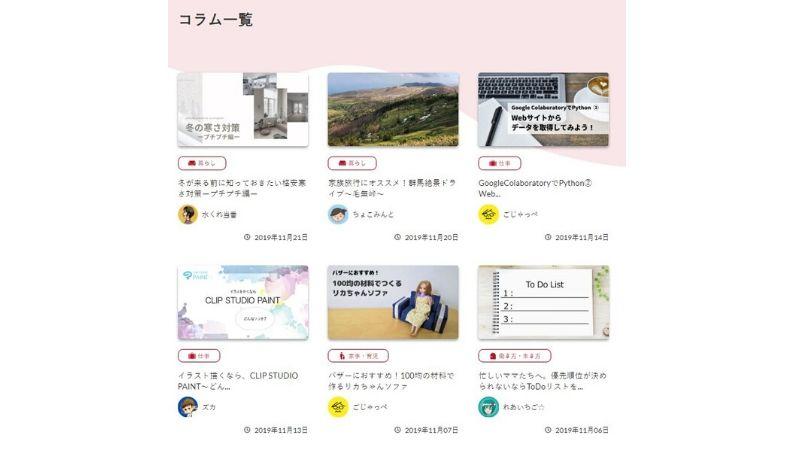
前回と同様にWaMのサイトから、コラム一覧ページ(https://wam-pjt.jp/colum/)のデータを取得し、コラムのタイトルと掲載日をCSVファイルに保存したいと思います。
サイトからHTMLデータを取得する
まずは目的のサイトからデータを取得しましょう。今回は一つの記事のかたまりであるarticleタグとそのクラスであるarticleEntryを指定してコラム記事のデータを取得します。

データの列を設定する
今回は記事の中からタイトルと掲載日をCSVファイルに保存したいと思います。保存するCSVファイルはこんなイメージです。

イメージに合わせてpandasのDataFrameに列をセットします。

必要なデータを取り出し、pandasに格納する
BeautifulSoupオブジェクトから必要なデータを取り出します。今回は掲載日とタイトルを取得したいので、ブラウザの「検証」モードから掲載日とタイトルのタグを調べます。掲載日はtimeタグ、タイトルはh2タグであることが分かります。
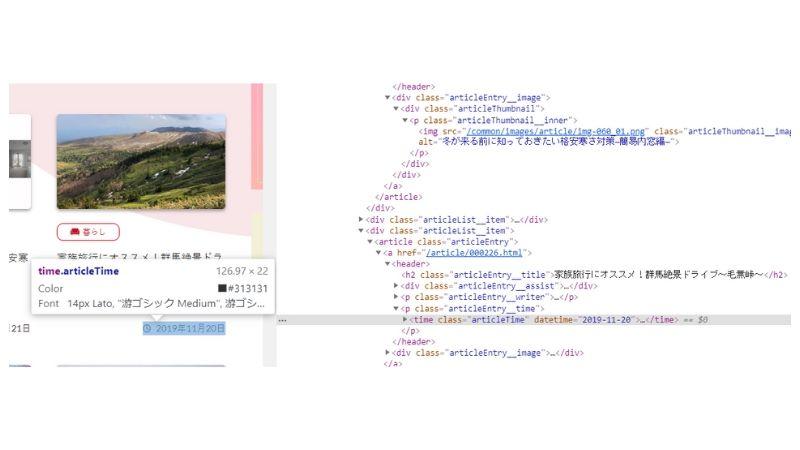
取得したデータをfor文で1つずつチェックし、timeタグ、h2タグを指定して、データを取り出します。取り出したデータをpandasに格納し、pandasに行を追加しておきます。

CSVファイルに保存する
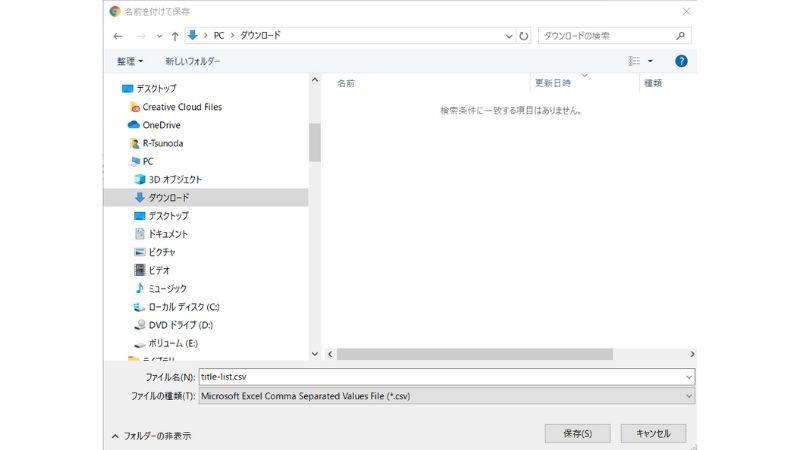
csvファイル名とエンコードを指定し、files.downloadを実行します。

「名前を付けて保存」ダイアログが表示されるので、ファイルを保存してください。
保存されたファイルを開き、イメージ通りのCSVファイルが出来ていればOKです!
まとめ
いかがでしたか? Google ColaboratoryでPythonシリーズとして、Webサイトからデータを取得してCSVファイルに保存するまでを3回にわたり簡単にご説明しました。普段はPythonにあまり縁がない私にもできたので、「スクレイピングって難しそう......」と敬遠しているあなたにも絶対できるはず!ぜひチャレンジしてみてください。


